02
Featured Work
대표 프로젝트
Personal Project
Plugin · Workspace
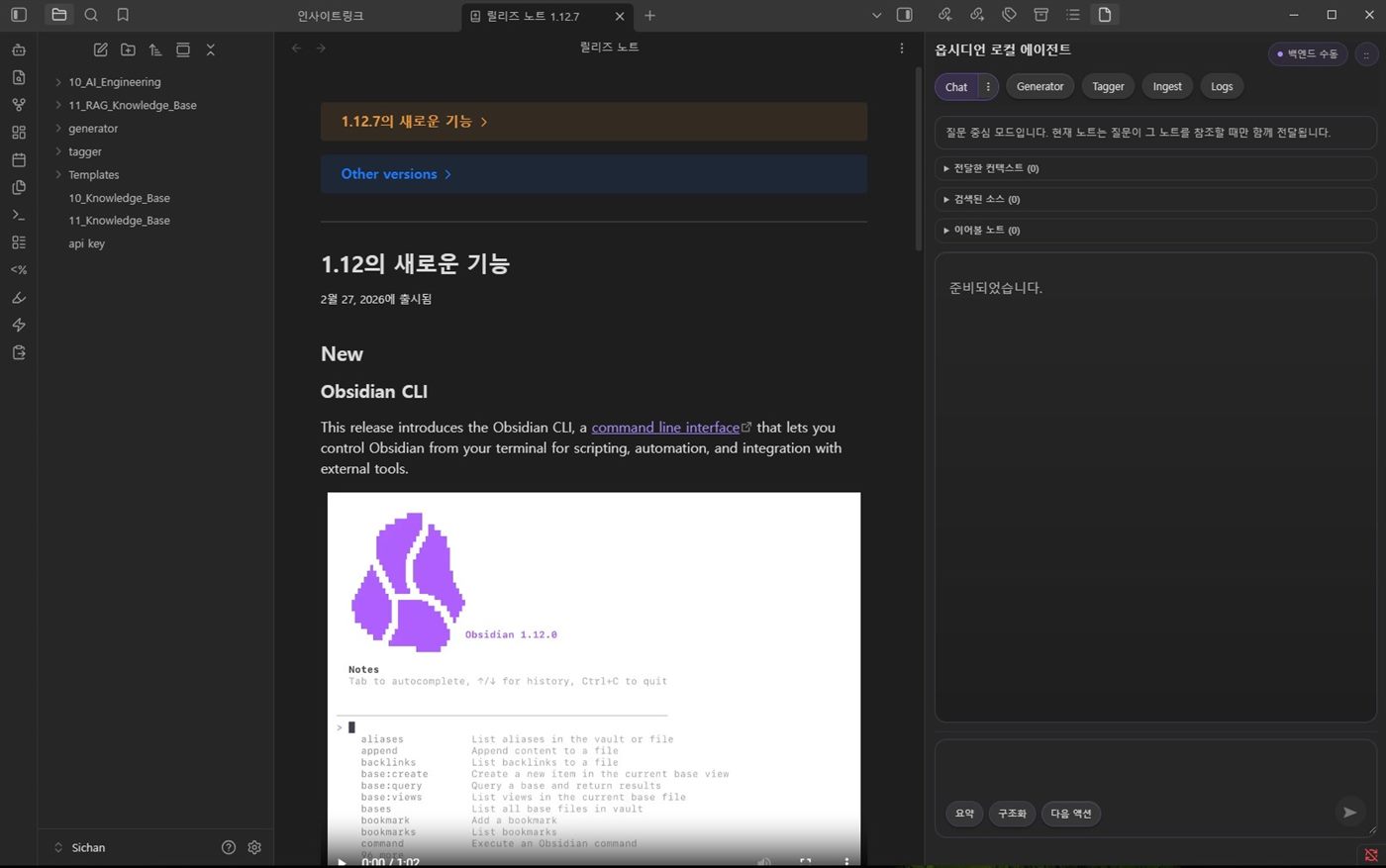
Obsidian RAG
기록을 구조화하고 relation chain을 검색, 추천, 액션으로 다시 연결한 Obsidian 기반 로컬 지식 워크스페이스입니다.
- V1 standalone chat에서 V2 in-note workspace로 확장
- typed relation runtime을 retrieval·recommendation·action·graph UI에 공통 재사용
Team Project
Generative AI
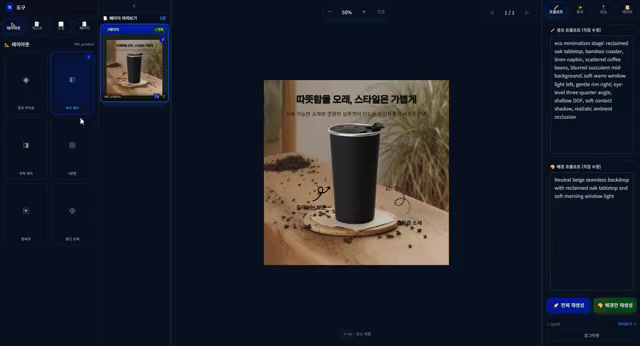
상세페이지 자동 기획·생성 시스템
입력 정보로 기획, 생성, 수정 흐름을 잇는 생성형 AI 파이프라인입니다.
- AIDA 기반 생성 파이프라인과 단계별 재실행 구조
- OpenAI·Gemini failover와 페이지 단위 재생성 흐름
Personal Project
Trading Data · Ops
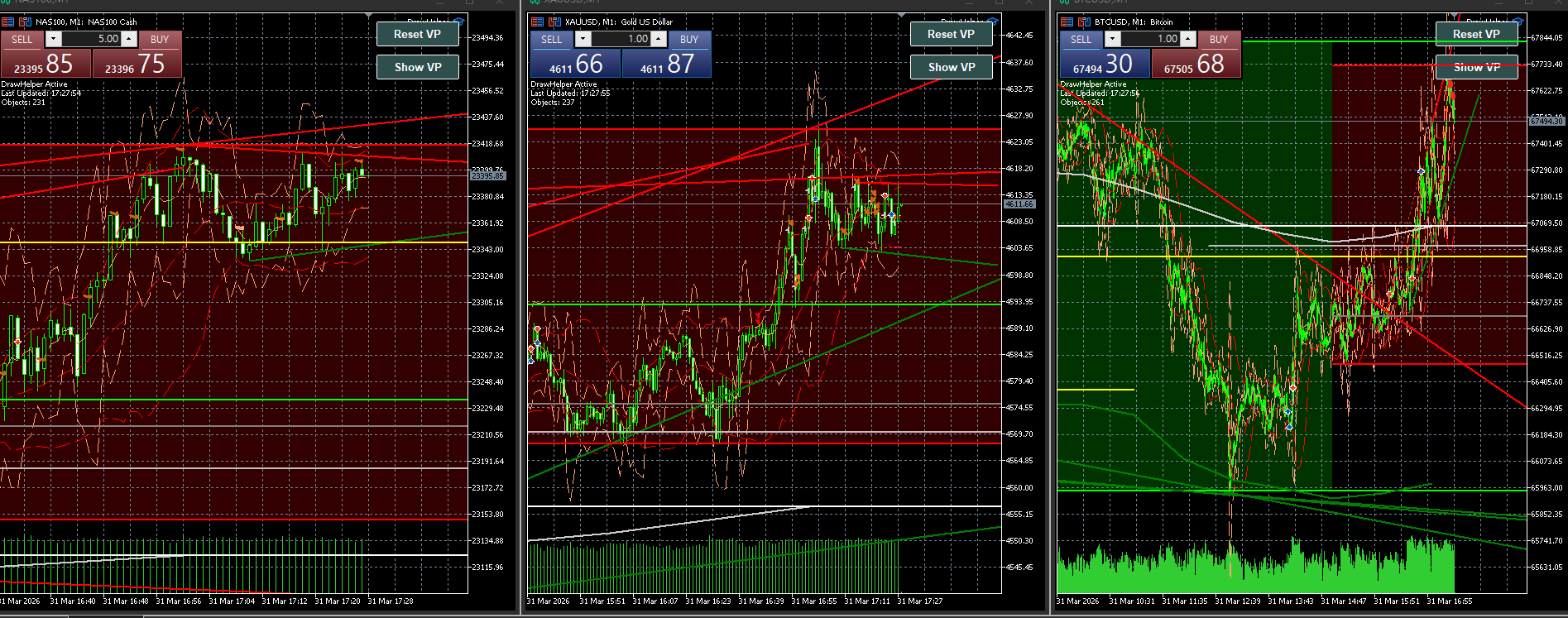
CFD 데이터 기반 트레이딩 시스템
차트의 위치와 반응을 lifecycle로 해석하고, 다시 teacher-state 25와 compact dataset으로 남기는 트레이딩 해석 프로젝트입니다.
- position -> response -> state -> forecast -> decision lifecycle 구조화
- teacher-state 25, micro-structure Top10, QA gate로 학습 가능 데이터화








